Beyond the Prompt: How Multi Language Models Like GPT-4o and Gemini Are Learning to See, Hear, and…
For the past few years, AI conversation has been dominated by large language models (LLMs) processing and generating text or diffusion…


Beyond the Prompt: How Multi Language Models Like GPT-4o and Gemini Are Learning to See, Hear, and Code Our World
For the past few years, AI conversation has been dominated by large language models (LLMs) processing and generating text or diffusion models conjuring images from prompts. Think ChatGPT, Claude, or Llama for text; Midjourney or Stable Diffusion for visuals. Impressive, but inherently limited—like trying to understand the world through only one sense.
The reality is, human understanding is multimodal. We process text, visuals, sounds, and context simultaneously. For AI to move beyond clever text generation or image synthesis towards more grounded reasoning and useful interaction, it needs to do the same.
Enter the era of Multimodal AI. This isn’t just about handling different data types; it’s about models that can ingest, process, and correlate information across various modalities — text, pixels, audio waveforms, video streams, code snippets, and more. The goal? To build AI systems with a richer, more contextual understanding, enabling applications far beyond what unimodal systems can achieve. Models like OpenAI’s GPT-4o, Google’s Gemini family, and Anthropic’s Claude 3 series are at the vanguard of this shift.
Unpacking Multimodality: From Data Silos to Fused Understanding
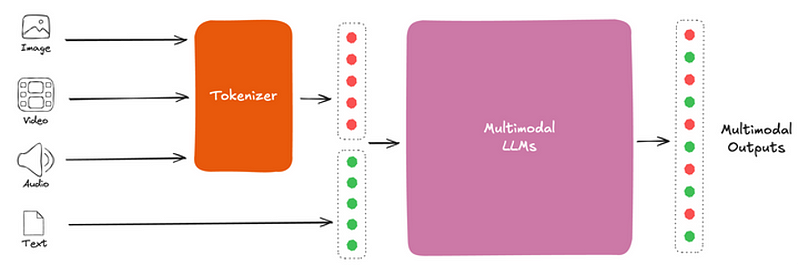
Traditional AI often treats data types in isolation. Multimodal AI aims to break down these silos. The core technical challenge lies in data fusion — creating unified representations (often complex vectors called embeddings) that capture the relationships between different modalities.
How? Techniques vary, but often involve:
- Specialised Encoders: Using architectures suited for each modality (e.g., Transformers for text, Convolutional Neural Networks or Vision Transformers for images, specialised networks for audio).
- Joint Embedding Spaces: Projecting embeddings from different modalities into a shared space where concepts align (e.g., the image of a dog is close to the word “dog”).
- Cross-Attention Mechanisms: Allowing the model to selectively focus on relevant parts of one modality while processing another (e.g., linking specific words in a caption to corresponding regions in an image).
The result is a model that doesn’t just see an image or read text, but understands how they relate to each other.
The Models Leading the Multimodal Charge (State of Play: May 2025)
Several major AI labs are pushing the boundaries here:
- OpenAI’s GPT-4o (“omni”): Released in May 2024, GPT-4o was designed with native multimodality at its core. Unlike predecessors that might bolt on vision capabilities, 4o processes text, audio, and image inputs and can generate outputs across these modalities within a single model. This powers features in ChatGPT like real-time voice conversations, where the AI can “see” what your camera sees, understand emotional tone in voice, analyse complex images or charts, and even generate code from visual mockups. Its companion image generation model (GPT Image 1, released early 2025) is also tightly integrated.
- Google’s Gemini Family (incl. 2.5 Pro): Google emphasises that Gemini was “built from the ground up” to be multimodal. The latest iteration, Gemini 2.5 Pro (March 2025), boasts impressive reasoning and coding skills alongside its multimodal foundation. It handles interleaved text, image, audio, and video inputs effectively (though API outputs are currently focused on text). Gemini excels at tasks requiring deep visual understanding, complex chart analysis, and long-context processing across modalities (thanks to its up-to-1-million-token context window). It’s the engine behind multimodal features in Google Search, Google Lens, and the Vertex AI platform tools.
- Anthropic’s Claude 3 Family (Opus, Sonnet, Haiku): While perhaps best known initially for its large context window and strong text reasoning, the Claude 3 family (March 2024) possesses powerful vision capabilities. Models like Opus and the recently updated Claude 3.7 Sonnet can analyse complex images, diagrams, charts, and documents uploaded alongside text prompts with high accuracy. While current output is primarily text-based, its strength lies in extracting information and reasoning based on visual input, making it excellent for document analysis and visual Q&A.
Multimodal AI in the Wild: Beyond Demos
This isn’t just research; these capabilities are powering real-world tools:
- Next-Gen Search & Answer Engines: Tools like Perplexity leverage models like GPT-4o and Claude 3.7 to answer queries, citing web sources. While primarily text-focused in its core web product, its mobile assistant integrates camera/screen inputs, and file uploads (PDFs, etc.) allow for multimodal analysis. Google Search increasingly uses Gemini’s multimodal understanding for complex visual queries.
- Enhanced Productivity Suites: Microsoft Copilot, integrating OpenAI’s models across Microsoft 365, uses multimodality implicitly when generating a PowerPoint presentation (visuals/structure) from a Word document (text) or analysing data within an Excel spreadsheet (numerical/visual).
- Creative & Development Tools: ChatGPT, using GPT-4o, can generate detailed descriptions for images, brainstorm visual concepts, and translate UI mockups (images) into code. GitHub Copilot (potentially integrating vision) aims to understand visual elements in IDEs.
- Data Analysis Platforms: Tools are emerging that allow users to upload dashboards or charts as images and ask natural language questions, leveraging models’ visual analysis capabilities.
Why Multimodality is Technically Crucial
This shift is essential for several reasons:
- Improved Grounding: Connecting language to perceptual data (vision, audio) helps “ground” the AI’s understanding in something resembling the real world, reducing abstract errors and enhancing common sense.
- Richer Contextual Reasoning: Many tasks require integrating multiple data types. Think about understanding sarcasm (text + audio tone), following visual instructions, or debugging code based on an error message (text) and a screenshot (image).
- More Natural Interaction: Moving beyond the keyboard to interfaces involving voice, gesture (via cameras), and visual cues.
- Enabling Complex Applications: Robotics (visual navigation + commands), autonomous driving (sensor fusion), advanced medical diagnostics (images + reports + patient history), and truly adaptive educational systems.
The Hurdles Remain Significant
Despite the rapid progress, challenges persist:
- Computational Demands: Processing and aligning massive datasets across multiple modalities is computationally intensive and expensive.
- Data Alignment & Scarcity: Creating large-scale, high-quality datasets where different modalities are accurately aligned (e.g., precise temporal alignment of audio and video frames with text descriptions) is difficult.
- Robust Evaluation: Developing comprehensive benchmarks that truly measure cross-modal reasoning, beyond task-specific metrics, is an ongoing research area.
- Propagation of Bias: Biases present in datasets for any modality can interact and amplify in multimodal models.
- Scalability & Efficiency: Making these powerful models efficient enough for widespread deployment, especially on edge devices, is key.
A More Integrated AI Future
Multimodal AI isn’t just an incremental improvement; it’s a paradigm shift. Powered by sophisticated models like GPT-4o, Gemini 2.5, and Claude 3, AI is moving from being a specialised text processor or image generator to a more integrated system capable of perceiving and reasoning about the world in a richer, more connected way. While technical challenges remain, the fusion of modalities is undeniably paving the way for the next generation of more capable, context-aware, and ultimately, more useful artificial intelligence.